
In a previous post, I explored integration between Drupal 7 and SQL Server Reporting Services. In this post, I’ll examine how you can take advantage of the fact that Drupal 7 can be installed on SQL Server to store geographic data using SQL Server 2008’s spatial data support, and also how you can integrate Bing Maps and Twitter geographic data into your Drupal site.
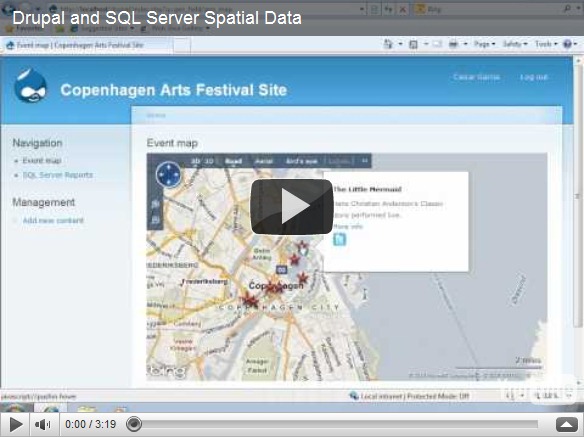
Microsoft introduced support for spatial data in SQL Server 2008 (see some of my past posts for details), and given that you can now install Drupal on Windows with a SQL Server content database, it makes sense to use this support to extend your Drupal site to include content with a geographical element. The scenario we decided to use when exploring this idea was a site for a local arts festival that includes the ability to publish details of events, including their location. However, you could easily adapt the idea for any content that has a location-based element. The video shows the solution we created (you can also view the video on YouTube).
Our solution not only incorporates spatial data that is stored in SQL Server, but also uses the Bing Maps control to visualize the spatial data, and retrieves tweets that include a geographic location from Twitter. This sort of “mash-up” approach where data and services from multiple sources on the Web are combined to create a rich user experience is the very essence of today’s most cutting edge Web applications, and when combined with the social/community-based publishing capabilities of Drupal it can be used to create some pretty compelling compelling solutions.
The diagram below shows the high-level architecture of the solution. Note that the SQL Server database forms the “data hub” of the application, storing the geographical data from both the Drupal content and the related tweets (which are retrieved and cached in the database periodically using the Cron scheduler in Drupal).

At the heart of the solution is a set of custom Drupal modules that we implemented in PHP. These are packages and installed in the Drupal site to add the required spatial data functionality. The first module we created, and the one on which the others all depend, is a module named GeoField that defines a Location field type that can be included in Drupal content types. The Location field type stores a geographical Longitude-latitude point in well-known text (WKT) format, which can easily be instantiated as a SQL Server geography data type instance. The module also defines a widget for setting Location values, which consists of a textbox and a Bing Maps control. Users can enter an address in the text box and geocode it using the Bing Maps API, or they can right-click a point on the map and reverse-geocode the address. The code to do the geocoding is implemented in JavaScript as described in a previous blog post. The following PHP functions define the field info and schema within Drupal:
function geo_field_field_info() {
return array(
'geo_field_Location' => array(
'label' => t('Location Data'),
'description' => t('A field for storing geographic data.'),
'default_widget' => 'geo_field_bingmap',
'default_formatter' => 'geo_field_simple_text',
),
);
}function geo_field_field_schema($field) {
$columns = array(
'location' => array('type' => 'varchar', 'length' => 255, 'not null' => FALSE),
);
$indexes = array(
'location' => array('location'),
);
return array(
'columns' => $columns,
'indexes' => $indexes,
);
}
The Bing Maps widget, and an alternative simple textbox-based widget, is defined with the following PHP code:
function geo_field_field_widget_form(&$form, &$form_state, $field, $instance, $langcode, $items, $delta, $element) {
$value = isset($items[$delta]['location']) ? $items[$delta]['location'] : '';
$element += array(
'#delta' => $delta,
);
$element['location'] = array();switch ($instance['widget']['type']) {
case 'geo_field_bingmap':
drupal_add_js('http://dev.virtualearth.net/mapcontrol/mapcontrol.ashx?v=6.3', 'external');
$element['location'] += array(
'#prefix' => '',
'#attributes' => array('class' => array('edit-field-geomap')),
'#attached' => array(
'js' => array(drupal_get_path('module', 'geo_field') . '/BingMaps.js'),
),
'#suffix' => '<div class="bing-map-control form-item form-type-textfield"><label for="txtAddress">Address</label><input type="text" id="txtAddress" class="form-text bing-map-address" size="60"/><input type="button" value="Find" class="location-search-button form-submit" class="form-submit" /><br/><div id="mapDiv" class="bing-map-edit bing-map" style="position:relative; width:400px; height:300px;"></div></div>',
);
case 'geo_field_geotext':
$element['location'] += array(
'#prefix' => '<div class="geo_field_geotext" style=" margin-top:20px; border: thin solid #808080;"><p>Enter a location:</p>',
'#type' => 'textfield',
'#default_value' => $value,
'#size' => 50,
'#maxlength' => 255,
'#suffix' => '</div>',
);
break;}
return $element;
}
Note the reference to the Bing Maps API and to the BingMaps.js JavaScript file, which includes the code used to handle the user interaction with the Bing Maps control.
The next task was to create a GeoEvent module that defines a content type for a festival event. This content type includes a Location field as well as more standard Drupal fields, such as a title, image, description, tags, and a simple text field to specify the date and time of the event.
The final module to be created was the GeoMap module, which defines the Event Map page on which events and tweets are plotted. The code in this module includes the following function, which retrieves the events from the Drupal database and returns them as a GeoRSS feed that can be imported into the Bing Maps control by client-side JavaScript code.
function geo_map_events() {
global $base_url, $language_content;
$results = db_query(
'SELECT r.title, b.body_value what, r.nid, w.[event_location_location] loc, geography::STPointFromText(w.[event_location_location], 4326).AsGml() [where] '.
'FROM node_revision r '.
'LEFT JOIN field_revision_body b ON r.nid = b.revision_id '.
'JOIN field_revision_event_location w ON w.revision_id = r.nid '.
'JOIN node n ON r.nid = n.nid '.
'WHERE n.type = \'event\'');
$items = '';
$addedItems = 0;
foreach ($results as $result) {
// We have to add in the namespaces here else the Bing control
// can't parse the content.
$xml = str_replace('<', '<gml:', $result->where);
$xml = str_replace('gml:/', '/gml:', $xml);
$description = $result->what != '' ? $result->what . '<br />' : '';
$description .= '<a href=\'index.php?q=node/' . $result->nid . '\'>More info</a> <br />';
$description .= '<a href="#' . $result->loc . '" class="twitter-button" > <img src="modules/geo_field/images/twitter.png" alt="Show nearby tweets" /> </a>';
$item_text = '<entry>'.
'<title>' . $result->title . '</title>'.
'<description>' . $description .'</description>'.
'<georss:where>' . $xml .
'</georss:where>'.
'</entry>';$items .= $item_text;
$addedItems++;
}if ($addedItems == 0) {
$placeholder_text ='<entry>' .
'<title>Placeholder</title>'.
'<description></description>'.
'<georss:where><gml:Point xmlns="http://www.opengis.net/gml"><gml:pos>-90 0</gml:pos></gml:Point>'.
'</georss:where>'.
'</entry>';
$items .= $placeholder_text;
}
$output = "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n";
$output .= "<feed xmlns='http://www.w3.org/2005/Atom' xmlns:georss='http://www.georss.org/georss' xmlns:gml='http://www.opengis.net/gml'>\n";
$output .=
"<title>Festival Events</title>\n".
"<subtitle>Events for the 2010 festival</subtitle>\n".
"<author>\n".
"<name>Drupal Administrator</name>\n".
"</author>";
$output .= $items;
$output .= "</feed>\n";drupal_add_http_header('Content-Type', 'text/xml; charset=utf-8');
print $output;
}
Note that the query used to retrieve the data uses the SQL Server geography type’s STPointFromText function to instantiate a geography instance from the WKT representation of each location, and the AsGml method to then convert that geography instance to Geographic Markup Language (GML) format. This enables the code to simply embed the GML representation of the location into the GeoRSS feed (since a GeoRSS feed is in effect an XML representation of a collection of GML entities). If no locations are found, a placeholder location is created to avoid returning an empty feed.
The client-side JavaScript to request this feed and display the results as a layer on the Bing Maps control is in a script file named EventMaps.js, which is referenced by the Drupal page:
function showEvents() {
eventLayer.DeleteAllShapes();
var url = "index.php?q=geo_field/items_georss";
var veLayerSpec = new VEShapeSourceSpecification(VEDataType.GeoRSS, url, eventLayer);
map.ImportShapeLayerData(veLayerSpec, function(feed) {
var numShapes = feed.GetShapeCount();
for (c = 0; c < numShapes; c++) {
var shape = feed.GetShapeByIndex(c);
if (shape.GetDescription() == 'Placeholder' &&
shape.GetTitle() == 'Placeholder') {
eventLayer.DeleteAllShapes();
}
shape.SetCustomIcon("modules/geo_field/images/pin.png");
}}, false);
map.SetCenterAndZoom(new VELatLong(55.67630968987942, 12.569355145096778), 10);
}
Note that if the layer contains only a placeholder location (because there were no events), the location is deleted to produce an empty map.
The GeoMap module also includes a function that queries Twitter to return any tweets containing a specified hash-tag (which the administrator can set in the settings for the module). These tweets are then inserted into a table in the SQL Server database. The table includes a geography column in which the location of the tweet is stored.
function tweets_download() {
$tweetsfeed = "http://search.twitter.com/search.json?q=%23" . variable_get('geomap_hashtag', 'drupalcon');
$results = json_decode(file_get_contents($tweetsfeed), TRUE);
// Insert items into the table if they're not already there.
$insertquery =
"IF NOT EXISTS ".
"(SELECT * FROM dbo.tweets WHERE TwitterID = :tweetid1) ".
"INSERT INTO dbo.Tweets VALUES " .
"(:datetime, :tweeter, :content, geography::GeomFromGml(:location, 4326), :tweetid2)";
foreach ($results['results'] as $tweet) {
if ($tweet['geo'] != null) {
$pointdetails =
"<Point xmlns='http://www.opengis.net/gml'><pos>" .
$tweet['geo']['coordinates'][0] . ' ' . $tweet['geo']['coordinates'][1] .
"</pos></Point>";
$timestamp = strtotime($tweet['created_at']);
$sqldate = date('c', $timestamp);
$sqldate = substr($sqldate, 0, strlen($sqldate) - 6);
$params = array(
'tweetid1' => $tweet['id'],
'tweetid2' => $tweet['id'],
'datetime' => $sqldate,
'tweeter' => $tweet['from_user'],
'content' => $tweet['text'],
'location' => $pointdetails);
db_query(
$insertquery,
$params);
}
}
}
Note that the Transact-SQL query executed by the code uses the SQL Server geography data type’s GeomFromGml function to convert the value retrieved from Twitter into a geography instance before storing it in the table. This function is called by the Drupal Cron scheduler, so the table of tweets is updated periodically.
When the user clicks the Twitter icon for an individual event, the following PHP function is used to retrieve the tweets within 500m of the event and return them as a GeoRSS feed to be displayed on the map.
function geo_map_tweets_feed($location) {
// Use the location functionality in MSSql to query all tweets near a given
// location.
$results = db_query(
'SELECT Tweeter + \' (\' + cast(TweetDateTime as nvarchar(50)) + \')\' as tweeter, '.
'Tweet as tweet, '.
'TweetLocation.AsGml() as [where] '.
'FROM tweets '.
'WHERE TweetLocation.STIntersects(geography::STPointFromText(\'POINT(' . $location . ')\', 4326).STBuffer(500)) = 1');
$items = '';
$found = false;
foreach ($results as $result) {
$found = true;
$xml = str_replace('<', '<gml:', $result->where);
$xml = str_replace('gml:/', '/gml:', $xml);$item_text = '<entry>'.
'<title>' . $result->tweeter . '</title>'.
'<description>' . $result->tweet .'</description>'.
'<georss:where>' . $xml .
'</georss:where>'.
'</entry>';$items .= $item_text;
}
if (!$found) {
$items = '<entry>'.
'<title>Placeholder</title>'.
'<description>Placeholder</description>'.
'<georss:where><gml:Point xmlns="http://www.opengis.net/gml"><gml:pos>-90 0</gml:pos></gml:Point>'.
'</georss:where>'.
'</entry>';
}$output = "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n";
$output .= "<feed xmlns='http://www.w3.org/2005/Atom' xmlns:georss='http://www.georss.org/georss' xmlns:gml='http://www.opengis.net/gml'>\n";
$output .= "<title>Festival Events</title>\n".
"<subtitle>Events for the 2010 festival</subtitle>\n".
"<author>\n".
"<name>Drupal Administrator</name>\n".
"</author>";
$output .= $items;
$output .= "</feed>\n";drupal_add_http_header('Content-Type', 'text/xml; charset=utf-8');
print $output;
}
Note that the WHERE clause of the Transact-SQL query executed by the code uses the STIntersects and STBuffer methods of the geography data type to find tweets within a 500m buffer of the event (which is instantiated as a geography instance by using the STPointFromText method as before).
As with the Reporting Services demo I blogged about previously, this solution we built was based on pre-beta releases of Drupal 7 and the related SQL Server driver for PDO and SQL Server module. To avoid the inevitable versioning issues that tend to arise with pre-release code dependencies, I haven’t includes the full source code. The plan is to publish it on CodePlex when the final release of Drupal 7 and the associated SQL Server components is available. Until then, hopefully you’ll find this article useful as an insight into the kinds of spatial data solutions you can build with Drupal and SQL Server.


















