Google Maps provides a really simple way to display geographical information, such as a set of pinpoints or a route, in the context of the surrounding geography, and developers can use it for free on Internet-facing sites. If you have data stored in Microsoft SharePoint products or technologies that includes geographical information, you should consider if a map display might help your users. I'm going to show you how to use Google Maps with the SharePoint user interface and demonstrate some simple coding techniques.
Microsoft's flagship SharePoint product is Microsoft Office SharePoint Server 2007 but you could easily use maps in the free Windows SharePoint Services 3.0 or other products based on SharePoint, such as Search Server 2008.
Take a good look at all the mapping solutions before starting to code. You may prefer Virtual Earth's user interface or find that Yahoo! Maps have more detail in a location that is important to you. I've coded Google Maps for a customer, and it is the most popular solution, but if you chose Virtual Earth instead the only difference would be in the JavaScript code I describe.
I'll concentrate on the use of Google Maps to display search results but the methods described can be applied other sources of data such as a SharePoint list, an Excel spreadsheet, or a Business Data Catalog (BDC) connection.
General Architecture
SharePoint is built on the ASP.NET 2.0 server-side development technology and its user interface is built from ASP.NET Web Parts. Web Parts allow administrators and users to customize the user interface to match their needs. They can add or remove Web Parts or rearrange them on the page. In the Web Part Gallery, site administrators can control which Web Parts are available. When you develop user interface components for SharePoint you should create them as Web Parts to inherit this flexibility automatically. You should also consider whether to create more than one Web Part to encapsulate different aspects of functionality that users can easily differentiate.
As an example consider a search tool for geographical data. When the user clicks "Search" the tool presents a list of results that match their terms as you might see in an Internet search engine or the SharePoint Search Center. However this tool also presents a Google map with the results pinpointed. This tool might warrant three Web Parts; one for the search terms, one for the results in a list, and a final one for the results on a map. In this architecture users or administrators could show just the list, just the map, or both displays.
Unlike Web Parts, Google Maps are coded in client-side code. JavaScript is used in the browser to create and position the map, add pinpoints, add captions, and draw shapes. This is what makes life interesting. Your Google Maps SharePoint solution must address how to communicate between server-side Web Parts and client-side JavaScript. You could, for example, publish a Web Service on the server and have client-side code query it and present results. AJAX would provide a lot of help with this. In the method I used, a server-side Web Part generates XML and renders it as an island amongst the SharePoint HTML. In the browser, JavaScript can locate this island and use it to draw the map and add pinpoints.
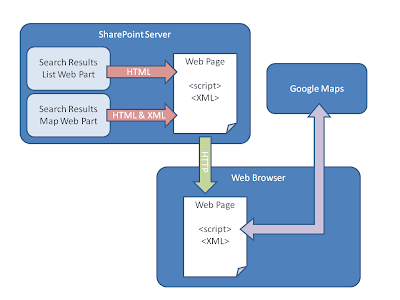
Search Results Web Part
In most search tools, results are presented in a list with links to each, a short description, and sometimes other fields. To build a SharePoint Web Part that displays search results, you submit a query by using a Microsoft.SharePoint.Search.Query.FullTextSqlQuery object. This returns a ResultTable object through which you must loop to evaluate each individual result and display them to users.
XML Data Island
As your code loops through the ResultTable, you can build the XML to place as an island in the Web page that will be returned to the client. To do this, create a System.Xml.XmlWriter object and configure it with a corresponding XmlWriterSettings object:
//Create the XML Writer Settings for configuration
XmlWriterSettings settings = new XmlWriterSettings();
settings.Encoding = System.Text.Encoding.UTF8;
settings.Indent = true;
settings.OmitXmlDeclaration = true;
//This string builder will be used to render the XML
resultsForMap = new StringBuilder();
//Create the XML writer
XmlWriter writer = XmlWriter.Create(resultsForMap, settings);
Then you can write the start element for your XML:
writer.WriteStartElement("MapResults", "my.namespace");
Looping through the DataRow objects in the ResultTable.Rows collection, you can add XML elements with the properties you need. For example:
foreach (DataRow currentResult in myResults.Rows)
{
writer.WriteStartElement("Result");
writer.WriteElementString("Title",
currentResult["Title"].ToString());
writer.WriteElementString("Path", path);
writer.WriteElementString("Latitude",
currentResult["SupplierLatitude"].ToString());
writer.WriteElementString("Longitude",
currentResult["SupplierLongitude"].ToString());
writer.WriteEndElement();
}
You must remember to end the XML and flush the writer:
writer.WriteEndElement();
writer.Flush();
Your XML is now flushed to the StringBuilder object (named resultsForMap in the above example). To render this string on the SharePoint Web page you can use an ASP.NET Label like this:
returnedXmlLabel.Text = "<xml id="\">" +
resultsForMap.ToString() + "</xml>";
The ID you use for this XML island allows JavaScript code to locate it when the map is rendered on the client.
Map Results Web Part
Since the work of populating the map with points and captions is done in client-side code, there is little to be done in ASP.NET code for the Map Results Web Part. However it is necessary to render a <div> tag for the map, and a <script> tag for the Google Maps code library. This <script> tag is where you must render the Google Key associated with your Google Maps account.
protected override void Render(System.Web.UI.HtmlTextWriter writer)
{
//Render the script tags that link to Google Maps API
writer.WriteLine(String.Format("<script " +
src="\http://maps.google.com/maps?" +
file="api&v=2&key={0}\ " +
type=\"text/javascript\"> </script>",
"Your key here" ()));
//Render the div that will display the map
writer.Write("<br /><div id=\"map\" " +
"style=\"width: 800px; height: 600px\" ></div>");
}
Registering and Embedding the Scripts
In the Map Results Web Part, you must also ensure that the JavaScript, which generates the map and populates it with pinpoints, executes when the page reaches the client. ASP.NET 2.0 provides an elegant way to do this: you can embed script files as resources in the same assembly as the Map Results Web Part. This makes deployment simple, because the script is part of the assembly.
You must complete several steps to embed a script file in your Web Part assembly:
Add a JavaScript file to the Visual Studio project and write the JavaScript Code.
This file is where you place all the Google Maps code. For examples of such code, see "JavaScript Files" below.
Add Web resource entries to the AssemblyInfo.cs file.
This file contains information about the assembly such as version numbers. You can add a reference to a script file like this:
[assembly: WebResource("MyNameSpace.MapScripts.js",
"text/javascript", PerformSubstitution = true)]
In your Map Results Web Part, register the script resource.
You should do this in the OnPreRender method:
protected override void OnPreRender(EventArgs e)
{
//Register the JavaScript file
Page.ClientScript.RegisterClientScriptResource(
this.GetType(), "MyNameSpace.MapScripts.js");
}
Make sure the script runs whenever the page loads.
You do this by registering the script as a startup script. Add the following line to the Map Result Web Part in the Render method:
this.Page.ClientScript.RegisterStartupScript(
this.GetType(), "MapScriptsStart", "loadMap();", true);
JavaScript Files
We now have an XML island rendered in the SharePoint Web Part that contains all the results that must appear on the map. We have also embedded a JavaScript file in the Web Part assembly to execute when the page loads on the client. The final task is to write JavaScript in the embedded file that loads the Google Map and add pinpoints and other objects.
Loading the Map
First, create a global variable to reference the map itself. You will need this throughout the script file:
var map;
Next create a function to load the map. This should match the function you specified in the RegisterStartupScript method in the previous section:
function loadMap(){
//Create the map
map = new GMap2(document.getElementById("map"));
//Centre it on default latitude and longitude.
map.setCenter(new GLatLng(54.59088, -4.24072), 16);
//Set a default zoom level
map.setZoom(5);
//Add the controls
var mapControl = new GLargeMapControl();
map.addControl(mapControl);
map.enableScrollWheelZoom();
map.addControl(new GMapTypeControl());
map.setMapType(G_SATELLITE_MAP);
//Parse the XML in the HTML data
parseXmlIsland();
}
Parsing the XML Island
The last line of the above code calls a separate parseXmlIsland function. This function locates the XML island and loads it into a variable. This must be done slightly differently depending on the user's browser:
var xmlIsland;
try //Internet Explorer
{
xmlIsland = new ActiveXObject("Microsoft.XMLDOM");
}
catch (e)
{
try //Firefox, Mozilla, Opera etc.
{
xmlIsland =
document.implementation.createDocument("", "", null);
}
}
xmlIsland.async = "false";
xmlIsland.validateOnParse = "false";
xmlIsland.loadXML(document.getElementById("resultsformap").innerHTML);
Setup some variables and get all the results nodes you placed in the XML:
var Title, Path, Latitude, Longitude;
var resultNodes = xmlIsland.getElementsByTagName("Result");
Now, loop through the node, storing relevant information:
var resultNode;
var resultNodeChild;
for (i = 0; i < resultNodes.length; i++) {
resultnode = resultNodes[i];
for ( j = 0; j < resultNode.childNodes.length; j++) {
resultNodeChild = resultNode.childNodes[j];
switch (resultNodeChild.nodeName) {
case "Title":
Title = resultNodeChild.text;
break;
case "Path":
Path = resultNodeChild.text;
break;
case "Latitude":
Latitude = parseFloat(resultNodeChild.text);
case "Longitude":
Longitude = parseFloat(resultNodeChild.text);
break;
}
}
//Add a point for this result
addPinPoint(Title, Path, Latitude, Longitude);
}
Adding Pinpoints
The above code calls the addPinPoint function for every result in the XML island. This function adds a pinpoint to the Google map in the standard way:
function addPinPoint(Title, Path, Latitude, Longitude){
//Set up the icon
var myIcon = new GIcon(G_DEFAULT_ICON);
//Select the right icon
myIcon.image = "mapimages/myPinPointIcon.png";
myIcon.iconSize = new GSize(12, 30);
myIcon.shadow = "mapimages/myPinPointShadow.png";
myIcon.shadowSize = new GSize(23, 30);
myIcon.iconAnchor = new GPoint(6, 30);
markerOptions = { icon:myIcon };
//Formulate the HTML that goes into the caption window
var infoHtml = "<a href="http://www.blogger.com/">" + Title + "</a>";
//Add the marker
var point = new GLatLng(Latitude, Longitude, false);
var marker = new GMarker(point, markerOptions);
//Add an info window
GEvent.addListener(marker, "click", function () {
marker.openInfoWindowHtml(infoHtml);
});
//Add the overlay
map.addOverlay(marker);
}
Licensing Considerations
The techniques I've outlined illustrate that Google Maps can be easily integrated into a SharePoint site and become a valuable addition to SharePoint functionality. However, before you develop such a solution, you must investigate licensing restrictions fully. This section describes the main issues and alternative map providers.
Licensing Google Maps
Google Maps is free for use on Internet-facing, non-subscription sites. If you use SharePoint to host your organisation's main Web site, or more targeted sites for departments, subsidiaries, or products, you can use Google Maps for no charge on pages with no access restrictions.
Google Maps does not allow free use on any password-protected page or on intranet sites. In such cases you can still use the technology, but you must take out a Google Maps for Enterprise license. Google Maps for Enterprise is licensed on a per-concurrent-user basis.
Microsoft Virtual Earth and Other Providers
Microsoft's Virtual Earth service competes directly with Google Maps and works in a similar way. There is an approximately equivalent set of features and maps are drawn and populated by using client-side code just like Google Maps. To use Virtual Earth with SharePoint your general approach can be identical to that described above although you must rewrite the JavaScript code to use the Virtual Earth classes and methods. On the intranet, Virtual Earth is licensed on the basis of total users.
Yahoo! also have a mapping service. This can be used free on both Internet and intranet sites so you should consider it carefully for SharePoint enterprise content management or knowledge management solutions restricted to your internal users. Yahoo! Maps cannot be used in applications for which you charge users. There are also other alternatives, such as PushPin.
Summary
Google Maps represents the easiest way to display geographical data on Web sites, including those hosted in Microsoft SharePoint products and technologies. If you carefully plan how to integrate the server-side SharePoint technology with the client-side Google Maps code, you can easily integrate the two and generate a rich user experience for geographical data.
Links
Windows SharePoint Services Developer Center
SharePoint Server Developer Center
Google Maps API Documentation


































